
Learning on the Edge - Federated Learning & Swarm Learning
Federated Learning und Swarm Learning in a Nutshell
Das Trainieren von Machine Learning-Modellen erfordert in der Regel größere Mengen an Daten. Das Teilen der dazu erforderlichen Daten mit Dritten ist für viele Unternehmen ein Schritt, der hinsichtlich Datenschutz mit Risiken verknüpft ist. Diese Lücke können Federated Learning und Swarm Learning Ansätze schließen, da sie auf der einen Seite Datenschutz und auf der anderen Seite Effizienz im Machine Learning zusammen bringen. Beide Methoden stellen Alternativen zum traditionellen, zentralisierten Training von Machine Learning Model-len dar, indem sie auf verteilten Systemen basieren. Sowohl Federated Learning als auch Swarm Learning ermöglichen das Training von Modellen über mehrere Geräte, ohne dass sensible Daten geteilt oder zentral gespeichert werden müssen. So ist Privacy by Design bei beiden Ansätzen ein zentrales Augenmerk. Während Federated Learning eine Zusammenarbeit zwischen lokalen Geräten und einem zentralen Server voraussetzt, nutzt Swarm Learning eine peer-to-peer-Struktur ohne zentralen Koordinator.
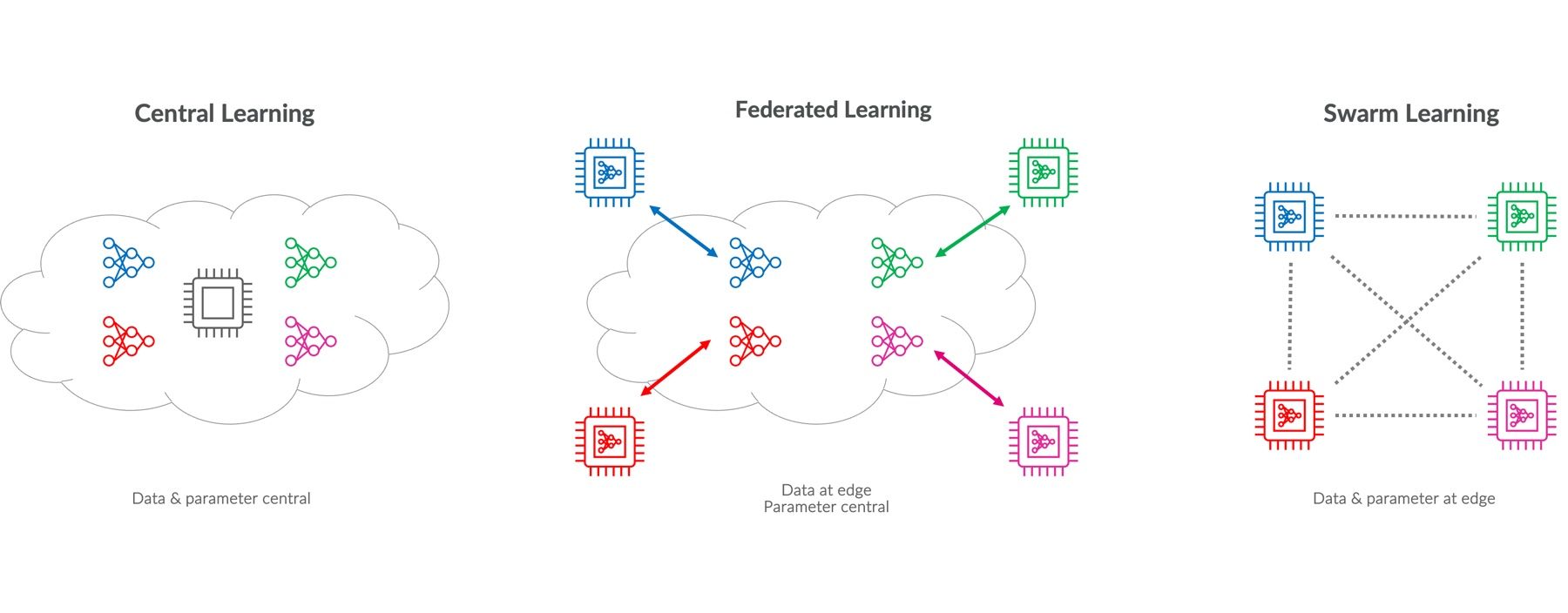
Zentrales Modell-Training im Vergleich zu Federated Learning und Swarm Learning
Was ist Federated Learning?
Federated Learning ist eine Methode des Machine Learning, bei der ein Modell über mehrere dezentrale Nodes trainiert wird. Dabei bleiben die Daten lokal, so dass Datenschutz sichergestellt ist und keine großen Datenmengen übertragen werden müssen. Im Federated Learning trainiert jedes Gerät ein Modell auf seinen eigenen Daten und sendet nur die Updates der Modell-Parameter an einen zentralen Server. Dieser aggregiert die Updates zu einem globalen Modell, welches dann wieder an die Geräte zurückgesendet wird. Dieser Prozess wird iterativ wiederholt. Grundvoraussetzung ist ein Ausgangsmodell, dass initial allen Geräten zur Verfügung steht.
Was ist Swarm Learning?
Swarm Learning ist eine Erweiterung des Federated Learning-Konzepts. Anstatt die Modellupdates an einen zentralen Server zu senden, kommunizieren die Nodes in einem peer-to-peer-Netzwerk. Verbessert ein Gerät sein lokales Modell, teilt es die Änderungen direkt mit allen anderen Nodes. Dies geschieht beispielsweise über Gossip-Protokolle mit geringer Netzwerkbelastung. Im Kern des Swarm Learning stehen Blockchain-Technologien, die für die Aufzeichnung und Verifizierung von Modellupdates verwendet werden. Jeder Modellaustausch zwischen den Geräten wird als Transaktion in der Blockchain aufgezeichnet, was Manipulationen verhindert und Transparenz schafft. Smart Contracts können hierbei verwendet werden, um die Bedingungen für den Austausch von Modellinformationen festzulegen und durchzusetzen.
Wichtige Algorithmen und Techniken in Federated und Swarm Learning
Beim Federated Learning ist der Aggregationsalgorithmus von zentraler Bedeutung. Der vorherrschende Ansatz hierbei ist der Federated Stochastic Gradient Descent (FedSGD). In diesem Verfahren berechnet jeder beteiligte Node die Gradienten basierend auf seinem lokalen Datensatz und übermittelt diese nach jedem Trainingsschritt an einen zentralen Server. Der Server führt daraufhin eine Aggregation der Gradienten durch und aktualisiert das globale Modell. FedSGD zeigt eine hohe Eignung für Szenarien, die Echtzeit-Verarbeitung erfordern. Jedoch ist zu beachten, dass die Präzision des aggregierten Modells potenziell beeinträchtigt werden kann, insbesondere wenn eine starke Heterogenität in den lokalen Datensätzen vorliegt. Als Alternative bietet sich die Federated Averaging Methode (FedAvg) an. Dieser Ansatz stellt eine Erweiterung des FedSGD dar und ist darauf ausgerichtet, die Effizienz der Kommunikation zu erhöhen, indem jeder Node mehrere Trainingsschritte absolviert, bevor Modellaktualisierungen geteilt werden. Der zentrale Server berechnet anschließend den gewichteten Durchschnitt (weighted average) der resultierenden Modelle.
Federated und Swarm Learning in der Praxis
AI Frameworks wie TensorFlow Federated und Open Minded's PySyft ermöglichen die Umsetzung von Federated Learning in Python. Auch Intel's OpenFL und NVIDIA's NVFlare bieten flexible Lösungen und vielfältigen Modell-Support.
Ein prominentes Anwendungsbeispiel für Federated Learning in der Praxis ist Apples Implementierung von Wortvervollständigung auf ihren iOS-Geräten. Apple nutzt Federated Learning, um die Wortvorhersagefunktion ihrer Tastatur zu verbessern, ohne die Privatsphäre der Nutzer zu beeinträchtigen. Jedes iOS-Gerät trainiert das Wortvorhersagemodell lokal basierend auf den Eingaben des Nutzers. Auf diese Weise bleiben die Texteingaben und andere sensible Daten auf dem Gerät und werden nicht an Apple-Server gesendet. Durch das Training auf den Geräten lernen die Modelle aus der realen Nutzung und passen sich den individuellen Schreibstilen und Sprachgewohnheiten der Nutzer an. Bei der Aggregation der lokalen Modelle profitiert Apple unter Anderem, in dem der zentrale Wortschatz kontinuierlich erweitert und die Wortvorhersagefähigkeit immer weiter verbessert wird. Periodisch sendet jedes Gerät Modellverbesserungen – und nicht die Textdaten selbst – an Apple zurück. Das aktualisierte, verbesserte Modell wird dann wieder an die Geräte verteilt.
Swarm Learning hingegen befindet sich noch in einer frühen Entwicklungsphase. In einer wissenschaftlichen Studie des Universitätsklinikums der RWTH Aachen wurde Swarm Learning angewendet, um die Genauigkeit der Darmkrebsdiagnostik zu verbessern. Das Forschungsteam trainierte KI-Modelle unter Verwendung von histopathologischen Bilddaten von Patienten aus Irland, Deutschland und den USA. Diese Modelle zielten darauf ab, genetische Mutationen, die zu Krebs führen können, aus Bildern vorherzusagen. Die Leistungsfähigkeit dieser Modelle wurde mit Daten aus zwei unabhängigen Datensätzen aus Großbritannien validiert. Die Ergebnisse der Studie demonstrierten eine überlegene Vorhersageleistung der Swarm Learning-Modelle im Vergleich zu Modellen, die ausschließlich auf lokalen Daten trainiert wurden.
Federated und Swarm Learning - Ein Ausblick
Federated und Swarm Learning bieten signifikante Vorteile in Bezug auf Datenschutz und Datensicherheit, da sie das Training von maschinellen Lernmodellen ermöglichen, ohne sensible Daten zu zentralisieren oder zu teilen. Es gilt jedoch einige Herausforderungen zu bewältigen um ein solches Projekt erfolgreich umzusetzen. Nicht nur effizeinte Skalierung des Systems bei wachsender Anzahl von Nodes sondern auch Kommunikationseffizienz, sprich die Minimierung der Netzwerkbelastung und Optimierung der Datenübertragung sind entscheidend für den Erfolg. Die größte Hürde ist dennoch der Umgang mit unterschiedlichen Datenverteilungen über die Nodes hinweg (non-IID Problematik) und die damit verbundene Gefahr des Client Drifts. Hier gilt es den Aggregationsalgorithmus mit größter Sorgfalt zu implementieren, um ein qualitativ hochwertiges globales Model zu erhalten.
Im Zeitalter von immer größeren Datenmengen und der Wichtigkeit von Datensicherheit und Privatsphäre ermöglichen diese Technologien in Zukunft die effiziente Nutzung von Daten über verschiedene Geräte und Institutionen hinweg, ohne dabei Kompromisse einzugehen. Dadurch eröffnen sich neue Möglichkeiten für daten- und KI-gestützte Innovationen in sensitiven Bereichen wie dem Gesundheitswesen, die in dieser Form bisher nicht möglich waren.

Stefan Weingaertner
Stefan Weingaertner ist Gründer und Geschäftsführer der AltaSigma GmbH, einem Enterprise AI Plattform Anbieter. Mit über 25 Jahren Berufserfahrung in Machine Learning & AI zählt er zu den erfahrensten und renommiertesten Experten in dieser Domäne.
Stefan Weingaertner ist darüber hinaus Gründer und Geschäftsführer der DATATRONiQ GmbH, einem innovativen AIoT Lösungsanbieter für das Industrielle Internet der Dinge (IIoT).
Davor war er Gründer und Geschäftsführer der DYMATRIX GmbH und verantwortete die Geschäftsfelder Business Intelligence, Data Science und Big Data. Stefan Weingaertner ist als Dozent an verschiedenen Hochschulen tätig und Autor zahlreicher Fachbeiträge zum Thema AI sowie Herausgeber der Buchreihe “Information Networking“ beim Springer Vieweg Verlag. Er hat an der Universität Karlsruhe / KIT Wirtschaftsingenieurwesen studiert und berufsbegleitend an der LMU München einen Master of Business Research erfolgreich abgeschlossen.