
Erklärbare KI - Vertrauen durch Einblick in die Wirkweise von KI-Modellen
Erklärbare KI im Überblick
In der heutigen Zeit, in der die Künstliche Intelligenz (KI) zunehmend zur Entscheidungsfindung eingesetzt wird, die unser tägliches Leben beeinflussen, stellt sich eine zentrale Frage: Wie können wir den Entscheidungen von KI-Modellen vertrauen und sie verstehen? Basiert ein KI-Modell auf einem simplen statistischen Algorithmus, ist es meist einfach nachzuvollziehen, wie die Ergebnisse zustande kommen. Anders sieht es bei komplexen Modellen wie Deep Neural Networks (DNNs) aus. Aufbau und Entscheidungen dieser Modelle sind oft nicht ohne Weiteres nachvollziehbar. Explainable AI (XAI) greift dieses Problem auf. Doch wie genau kann XAI die "Black Box" solcher Modelle öffnen?
Explainable AI in a Nutshell
- Erklärbare AI (XAI) zielt darauf ab, die Entscheidungsprozesse und Funktionsweisen von KI-Modellen transparent und verständlich zu machen.
- Es ermöglicht Nutzern und Entwicklern, die Logik hinter den Vorhersagen und Entscheidungen der KI nachzuvollziehen, was essenziell für das Vertrauen und die Akzeptanz dieser Technologien ist.
- XAI unterstützt Entwicklern dabei, durch sinnvolle und verständliche Visualisierungen Modell-Wirkweisen zu plausibilisieren und unterstützt bei der Verbesserung von KI Modellen.
- Endanwender gewinnen Vertrauen, da die Wirkweise und Entscheidungsfindung von komplexen KI Modellen nachvollziehbar wird.
XAI - Einblick in das KI-Modell
Um zu verstehen wie ein spezifisches KI-Modell aufgebaut ist, gibt es Methoden und Techniken, die darauf abzielen, die internen Mechanismen und Funktionsweisen von KI-Modellen transparent und verständlich zu machen. Dieser Ansatz ist entscheidend, um die Komplexität und die sogenannte "Black Box"-Natur moderner KI-Systeme, insbesondere Deep Neural Networks offen zu legen. Dieser Einblick ist entscheidend, um Transparenz zu schaffen und das Vertrauen in die von KI-Systemen getroffenen Entscheidungen zu stärken. Insbesondere in kritischen Anwendungsfällen, wie im Gesundheitswesen oder in der Finanzbranche, ist es wichtig zu verstehen, wie ein Modell zu seinen Schlüssen kommt.
Sogenannte Stellvertreter-Modelle sind ein Weg die Funktionsweise eines zugrundeliegenden KI-Modells approximativ nachzubilden. Stellvertreter-Modelle sind dabei so gestaltet, dass sie leichter zu verstehen und zu interpretieren sind, ohne dabei auf wesentliche Informationen über die Entscheidungsfindung des Originalmodells zu verzichten. In der nachfolgenden Darstellung ist ein Stellvertreter-Modell in Form eines Decision Tree am Beispiel der AltaSigma AI Platform dargestellt.
Ein weiteres wichtiges Element ist die Betrachtung der Feature Importance. Dieser Aspekt befasst sich damit, wie stark einzelne Merkmale oder Eingabedaten das Ergebnis des KI-Modells beeinflussen. Durch die Analyse der Feature Importance können wir erkennen, welche Faktoren für das Modell am wichtigsten sind und wie diese die Vorhersagen oder Entscheidungen beeinflussen.
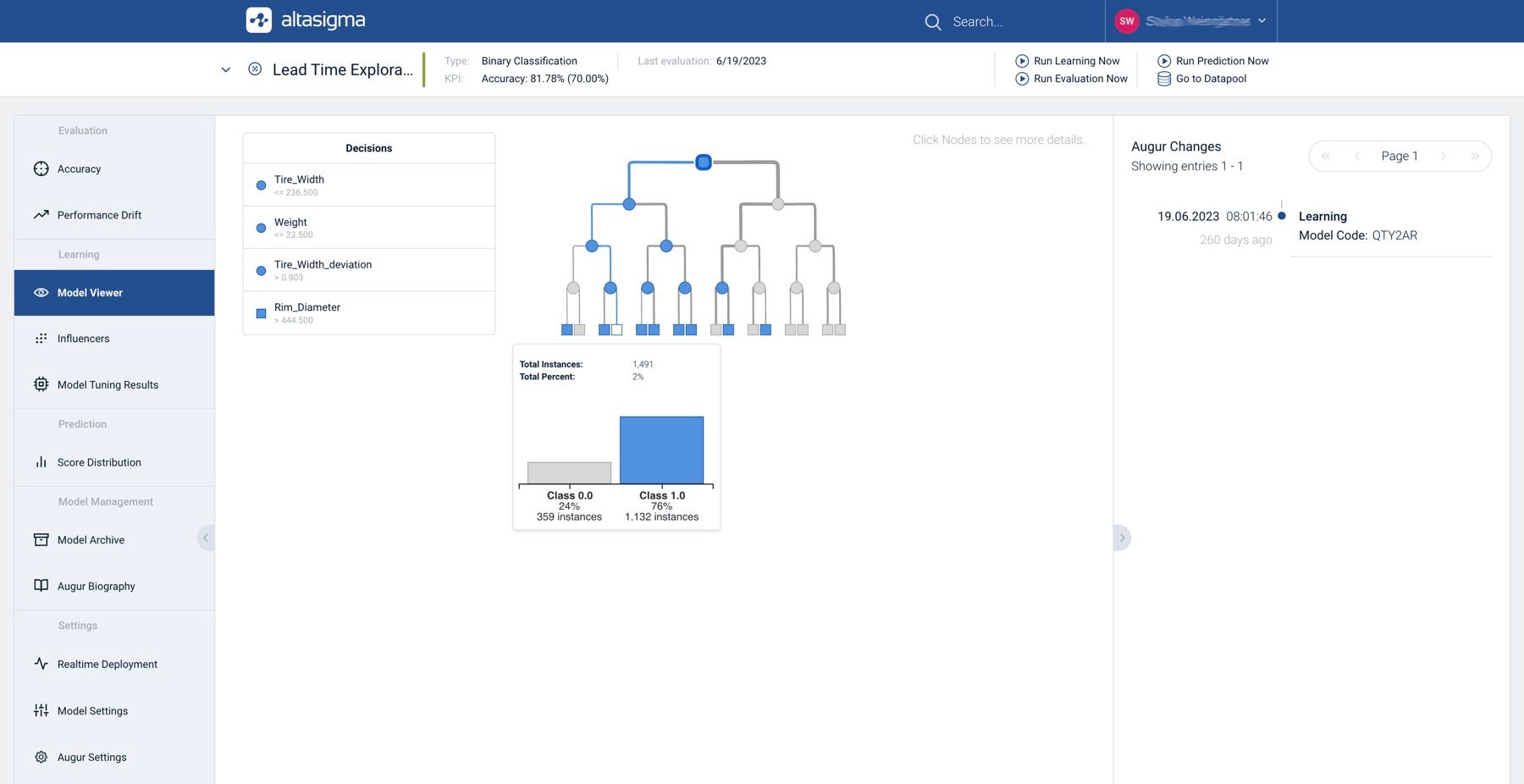
Decision Tree als erklärbares Stellvertreter-Modell eines DNN-Klassifikators
XAI - Einblick in die Entscheidung
Um die Entscheidungsfindungsprozesse von KI-Modellen nachvollziehbar zu gestalten, ist es unabdingbar, sowohl die interne Struktur als auch die spezifischen Mechanismen der Entscheidungsbildung zu verstehen. Hierfür bieten sich verschiedene methodische Ansätze an.
SHAP (SHapley Additive exPlanations), basierend auf spieltheoretischen Prinzipien, dient der Erklärung des Outputs beliebiger Machine Learning Modelle. Die zugrundeliegenden Shapley-Werte wurden ursprünglich 1951 vom amerikanischen Ökonomen Lloyd Shapley eingeführt und dienten der gerechten Gewinnverteilung in kooperativen Spielen. In der Anwendung auf Machine Learning repräsentieren die Shapley-Werte den relativen Beitrag jedes Features (als "Spieler" betrachtet) zur Gesamtleistung des Modells (dem "Spiel"). Die zentrale Idee von SHAP ist es, den Einfluss eines Features auf die Vorhersage zu bewerten, indem verglichen wird, wie die Vorhersage des Modells aussieht, sowohl mit als auch ohne das jeweilige Feature. Diese Differenz, resultierend aus der Präsenz oder Abwesenheit eines Features, wird als Shapley-Wert bezeichnet. Die Shapley-Werte bieten somit eine quantitative Bewertung des Einflusses jedes einzelnen Features auf die Vorhersage des Modells. Durch diesen Ansatz ermöglicht SHAP ein tieferes Verständnis dafür, wie verschiedene Eingabevariablen in ihrer Gesamtheit zur Leistung eines KI-Modells beitragen. Dies trägt wesentlich zur Transparenz und Nachvollziehbarkeit in der Welt des maschinellen Lernens bei.
LIME (Local Interpretable Model-agnostic Explanations) ist wie SHAP modell-unabhängig, orientiert sich aber an einem anderen Ansatz. Von der Funktionsweise her wird zunächst das Eingabebeispiel, für das eine Erklärung generiert werden soll, leicht modifiziert, um eine Menge ähnlicher Datenpunkte zu erzeugen. Anschließend beobachtet es, wie sich die Vorhersagen des Modells für diese modifizierten Daten ändern. Auf Basis dieser Beobachtungen erstellt es ein einfaches, interpretierbares Modell (wie ein lineares Modell), das lokal um das Eingabebeispiel herum gültig ist. Bei textbasierten Eingaben bedeuten diese Modifikationen beispielsweise das Hinzufügen oder Fehlen von Wörtern.
Reason Codes sind spezielle Codes oder kurze Erläuterungen, die die Gründe für eine spezifische Vorhersage oder Entscheidung eines KI-Modells darlegen. Sie dienen dazu, die Outputs von KI-Systemen für Endbenutzer verständlicher zu machen. Beispielsweise werden in der Finanzbranche Reason Codes verwendet, um Kredite und Risiken zu bewerten. In diesem Zusammenhang werden diese auch als Credit Score Risk Factors oder Adverse Action Codes bezeichnet. Diese numerischen oder alphanumerischen Codes sind mit verschiedenen Kreditbewertungsfaktoren verknüpft und werden von kurzen Beschreibungen begleitet, die erklären, was sich am stärksten auf diesen Score auswirkt. Die Reason Codes werden sortiert aufgeführt, wobei der Faktor, der den größten Einfluss hat, an erster Stelle steht. Reason Codes sind ein wesentlicher Bestandteil eines verantwortungsvollen KI-Modellmanagements und spielen eine entscheidende Rolle bei der Schaffung eines Rahmens für ethische und faire KI. Sie helfen, Vorurteile und Halluzination in KI-Modellen zu identifizieren und zu minimieren, indem sie den Einfluss von diskriminierenden Faktoren wie Geschlecht oder Alter auf die Modellvorhersagen transparent machen. Dadurch wird nicht nur die Genauigkeit der KI-Modelle verbessert, sondern auch das Vertrauen der Nutzer in diese Technologie gestärkt.
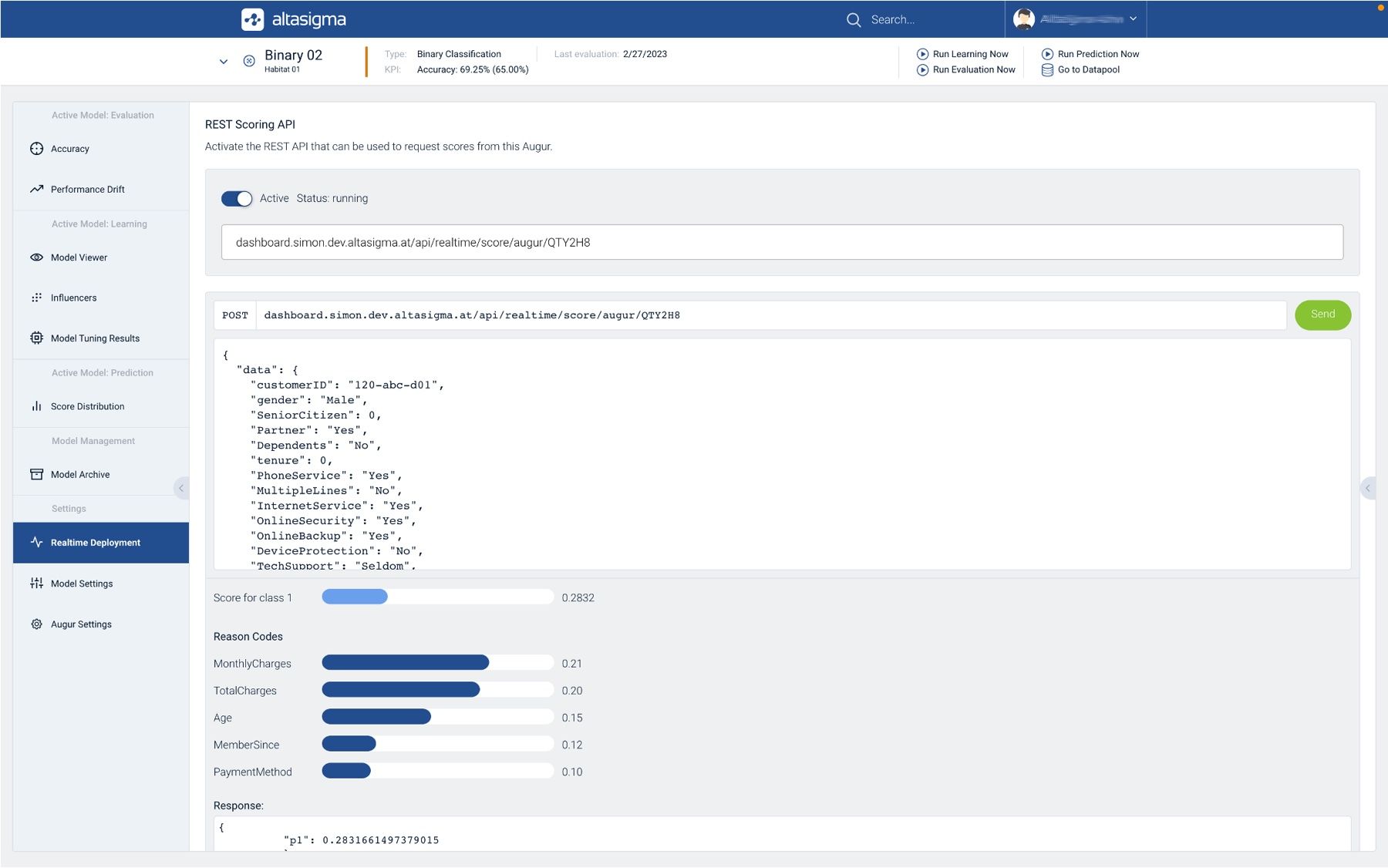
Modell-Inferenz mit REST API und Reason Codes am Beispiel der AltaSigma AI Platform
Herausforderungen und Perspektiven für die Zukunft
Die größte Herausforderung von Explainable AI (XAI) ist das Spannungsfeld zwischen komplexen und möglichst präzisen KI-Modellen auf der einen Seite und einer möglichst einfachen Verständlichkeit des Modell-Outputs auf der anderen Seite. Dabei gewinnen ethische Aspekte zunehmend an Bedeutung, da XAI in sensiblen Bereichen wie Medizin und Finanzen eingesetzt wird, wo faire und vorurteilsfreie Entscheidungen von entscheidender Bedeutung sind. In Zukunft wird XAI unverzichtbar sein, um Vertrauen in KI-Entscheidungen zu schaffen und ihre gesellschaftliche Akzeptanz zu sichern. Es geht darum, KI-Entscheidungen transparent, nachvollziehbar und ethisch verantwortungsvoll zu gestalten.

Stefan Weingaertner
Stefan Weingaertner ist Gründer und Geschäftsführer der AltaSigma GmbH, einem Enterprise AI Plattform Anbieter. Mit über 25 Jahren Berufserfahrung in Machine Learning & AI zählt er zu den erfahrensten und renommiertesten Experten in dieser Domäne.
Stefan Weingaertner ist darüber hinaus Gründer und Geschäftsführer der DATATRONiQ GmbH, einem innovativen AIoT Lösungsanbieter für das Industrielle Internet der Dinge (IIoT).
Davor war er Gründer und Geschäftsführer der DYMATRIX GmbH und verantwortete die Geschäftsfelder Business Intelligence, Data Science und Big Data. Stefan Weingaertner ist als Dozent an verschiedenen Hochschulen tätig und Autor zahlreicher Fachbeiträge zum Thema AI sowie Herausgeber der Buchreihe “Information Networking“ beim Springer Vieweg Verlag. Er hat an der Universität Karlsruhe / KIT Wirtschaftsingenieurwesen studiert und berufsbegleitend an der LMU München einen Master of Business Research erfolgreich abgeschlossen.